Regular expression is an invaluable technique that can be used in many situations to get the work done in more fast way. it is used in siem like splunk, ctf, programming languages etc.
the main theme of using regex is, it will help you to find out specific character or sequence of characters from a long garbage string.
you need to remember here everything is character. users write patterns to find out that character or sequence of character called string.
https://sodocumentation.net/regex/topic/639/lookahead-and-lookbehind
https://materials.rangeforce.com/tutorial/2019/12/26/Regular-Expressions/
https://www.regular-expressions.info/lookaround.html
https://regexone.com/problem/matching_phone_numbers
http://www.rexegg.com/regex-lookarounds.html
meta characters
^.[{\$()|*+? these are special characters called meta characters and have other special meaning. so if you need to find any string that contain the above characters, then you need to use \ backslash to escape that. for example, say i want to find out a string called abc? then how can i write the correct regex for this?
abc\?
character sets:
[abc] it will try to match either a or b or c
for example, [a] what does this mean? it will find out character a from the below line.
my name is avi.
Meta sequences:
when we need to deal with long and complex strings then meta sequences can help.
. dot also known as wildcard (not to mixup with * as wildcard. * called here as asterisk) --> it matches any characters like digit, word, letter, whitespace, everything except new line.
\d will match only digit. abc ac acb aob a2b a42c
\D will work inversely. abc ac acb aob a2b a42c
\w will match any word character a-z, A-Z, 0-9 including underscore. abc ac acb aob a2b a42c a_b~/?-&*$%
\W will work inversely as well. abc ac acb aob a2b a42c a_b~/?-&*$%
\s will match whitespace, tab, new line. for \S it will work just as the above two examples.
OR operator inside character sets [] | grouping ():
[abc] it will match either a or b or c

[abc_?] it will match either a or b or c or _ or ?
(materials|portal)\.rangeforce\.com
materials.rangeforce.com or portal.rangeforce.com
Ranges:
[a-zA-Z0-9_] --> this is basically how the \w works.
[a-fA-F0-5]
[a-c] - Matches a string that contains a, b or c
[a-fA-F0-9] - Matches a string that represents a single hexadecimal digit, case-insensitively -> Test it out!
[a-zA-Z0-9_] - This is basically how the word character (\w) is defined.
[0-9]% - Matches a string that has a character from 0 to 9 before a % sign
Except:
[^a-zA-Z] - Matches a string that doesn’t have a letter from a to z or from A to Z. In this case, the ^ is used as a negation of the expression which we call except -> Test it out! it will match everything except a-z and A-Z

NOTE: Inside bracket [] expressions, all special characters (including the backslash ) lose their special powers. Therefore, we will not apply the “escape rule”.
Quantifiers - * + ? and {}
[abc]\* --> * quantifier says the preceding characters may appear 0 to n times upto a defined boundary. it will also match the empty string means space. lets see the below examples.
[a-c]*@ --> here boundary is @
abcbcacacbb@gmail.com --> it will match like this. because * says the preceding character may appear 0 to n times.
see the below image as well to understand the same concept in different way:
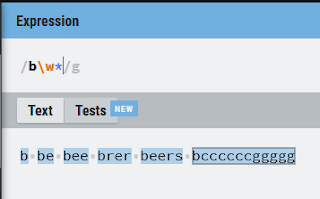
here b is already matched. now question is after b we have put \w. what does this mean? this means \w will match any character. now another question is how long? * says 0 to n times. when \w is 0 then it is selected only b.
[a-c]?@
abcbcacacbb@gmail.com --> it will match like this because ? says the preceding character may appear 0 or 1 times.

? quantifier says 0 or 1. when preceding character \w is 0 then only b is selected. when preceding character \w is 1 then others are selected.
[abc]\+ --> + quantifier works as same way as * but it says preceding character may appear at least once. and it will not match the empty string.
[a-c]+@
abcbcacacbb@gmail.com
+ quantifier say preceding character will appear 1 to more times. so if here \w is 0 then b will not be selected.
{} --> braces are used when you want to specify how many times the preceding characters should appear. you can set the limit or length. say phone number fields in a form only accepts digits that are exactly 10 digit. /^[0-9]{10}$/
abc* --> this means, match a string that has ab followed by zero or more c. so it will match ab abc abcc abccc
abc+ --> match a string that has ab followed by one or more c. it will not match string that has only ab. condition is string has to has ab and followed by one or more c. so abc abcc abcccc
abc? --> match a string that has ab followed by zero or one c. so ab abc
it will not match abcc. it will abc ab
abc{2} --> match a string that has ab followed by two c. it will not match abc ab abccc. it will only match abcc
abc{2,} --> match a string that has ab followed by two or more c. abcc abccccccc
it will not match abc ab
abc{2,5} --> match a string that has ab followed by 2 up to 5 c.
a(bc)* --> matches a string that has a followed by zero or more copies of sequence bc.
a(bc){2,5} --> matches a string that has a followed by two to 5 copies of sequence bc.
\d+ will match all digits. for example 12345
\d+45 will also match 12345. so what is the difference between these two? the 2nd one will only look for 45 digits along with some preceding digits.
Quantifiers example:
* means zero or more.
+ means one or more.
? means zero or one.
{3} exact number
{3,4} range of number minimum maximum
321-555-4321
123.555.1234
instead of writing \d\d\d.\d\d\d.\d\d\d\d to match the above phone numbers, we can write \d{3}.\d{3}.\d{4}
here we are using exact numbers. but sometimes we dont know what is the actual numbers so then we need to use other quantifiers.
so see below examples as well:
Mr. Schafer
Mr Smith
Ms Davis
Mrs. Robinson
Mr. T
Mr\. if we search like this then all Mr. will be highlighted. but we also need to match Mr (without dot) how can we match that? we can use quantifier ? because this means the preceding character may appear 0 or 1. here preceding character is . dot so now basically it says, there can be zero dot there or 1 dot there. when there is 0 dot then it will match Mr (without dot) and when there is 1 dot then it match Mr.
now to match capital name we can write [A-Z].
Mr. Schafer
Mr Smith
Ms Davis
Mrs. Robinson
Mr. T
now the above name will be highlighted up to the bold part. now we need to match the following name of the users. we can write \w. but see what happens when we put \w
Mr. Schafer
Mr Smith
Ms Davis
Mrs. Robinson
Mr. T
now you can see Mr. T come again unbold because it is expecting another character after T. as we dont know how many characters will be there for usernames so we can use quantifier *
Mr. Schafer
Mr Smith
Ms Davis
Mrs. Robinson
Mr. T
so now Mr\.?\s[A-Z]\w*
(Mr|Ms|Mrs)\.?\s[A-Z]\w*
or
M(r|s|rs)\.?\s[A-Z]\w*
another example:


this regex will also work to match email addresses.
Anchors - ^ $ \b : they are not actually match any characters, rather they match invisible position before and after character.
^The --> will only look for The word only the starting of any line. if The word places in the middle or end of the line then it will not match.
end$ -->only look for word in a end of a line.
\b --> called word boundary. look for word or line. i.e. if you want to find a sentense from the paragraph then you need to write \bmy name is avi\
see the below example also:
ha haha
\bha
then it will match ha haha
\Bha
then it will match ha haha
\bha\b
then it will match ha haha ; because this one only have word boundary before and after place.
Now lets do some examples:
321-555-4321
123.555.1234
we need to write regex pattern that match the above numbers.
we saw before that we can match any digit by using \d. if we use \d then it is going to match all of the digit in our file.
\d\d\d.\d\d\d.\d\d\d\d this will match the above two phone numbers.
123*555*1234
our regular expression will also match the above phone number 123*555*1234 pattern but we dont want that. so what we can do is using character set by using square braket:
\d\d\d[-.]\d\d\d[-.]\d\d\d\d
321--555-4321
\d\d\d[-.]\d\d\d[-.]\d\d\d\d
if we use double dash and use this regex pattern then it will not match. because in the character set it will search for either - or . in the 2nd - position it is expecting digit. so how can we write regex for that?
\d\d\d[-.]+\d\d\d[-.]\d\d\d\d
+ quantifier says the preceding character may appear 1 or more times.
say now we want to match 800 and 900
800-555-4321
900-555-4321
[89]00[-.]\d\d\d[-.]\d\d\d\d
Advanced technique
grouping and capturing:


Advanced techniques:
Back references: \1 it actually replace the double word.
\1 matches the same text that was matched by the first capturing group. now what do we mean by that? here 1st capturing group is (abc)

green color means put it on back reference. here 1st capturing group matches the text abc and put it on back reference (green color show that). now when we have duplicate text just like the abc again, and when we put \1 then it will take the duplicate abc and compare it with back reference. it will see that in back reference there is abc there. so it will delete the duplicate abc from the final output.

this regex will put cab into the first back reference.

but this one will not do that. this repeated capturing group will only capture the last iteration. because the + sign caused the pair of parenthesis to repeat 3 times. 1st time it stores c, 2nd time a and 3rd time b. and store b in the back reference. each time the previous value is overwritten so lastly b remains.

green color values are stored in the back references.
Useful Example: Checking for Doubled Words
When editing text, doubled words such as “the the” easily creep in. Using the regex \b(\w+)\s+\1\b in your text editor, you can easily find them. To delete the second word, simply type in \1 as the replacement text and click the Replace button.
lookaheads:
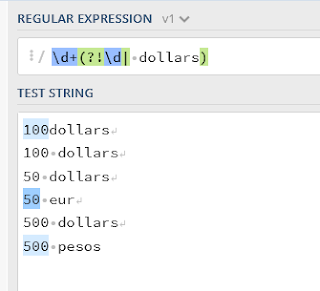
positive lookahead: syntax is ?=pattern
after digit (no matter how long the digit is because + is used) and space, if we found dollars then only we match the digit. If pattern match is found then look ahead to see what you are asked to match.

negative lookahead: syntax is ?!pattern
if the pattern matches then look ahead and dont match. for example, 123(?!456)
it will not match 123456 but it will match 123 or 123465
positive lookbehind: syntax is ?<=pattern

negative lookbehind: syntax is ?<!pattern
If pattern match then look behind and dont select that.

camel case:

Avi
Comments
Post a Comment